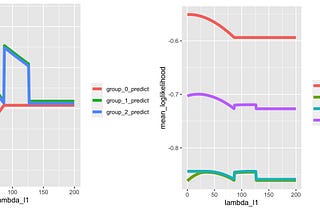
Mate PocsinTowards Data ScienceUnderstanding L1 Regularisation in Gradient Boosted Decision TreesA thorough look with an example in LightGBM and R·16 min read·Nov 1, 2022----
Mate PocsinTowards Data ScienceUnderstanding min_child_weight in Gradient Boosting Decision TreesDo you really know how this hyperparameter works?·8 min read·May 18, 2022--1--1
Mate PocsinTowards Data ScienceR Shiny GadgetsHow to help your RStudio work with interactive apps·7 min read·Apr 3, 2022----
Mate PocsinTowards Data ScienceUnderstanding How a Gradient Boosted Tree Does Binary ClassificationA step-by-step recalculation in LightGBM and R, from data to predictions, using the banknotes dataset·9 min read·Dec 4, 2021----
Mate PocsinTowards Data ScienceThis Week’s Unboxing: Gradient Boosted Models’ “Black Box”Step-by-step recalculation of the hidden model results, using R and LightGBM·16 min read·Nov 11, 2021--1--1
Mate PocsinTowards Data ScienceHow to Handle the Exposure Offset with Boosted TreesThree ways to move from GLM/GAM to a GBM model in insurance.·13 min read·Aug 28, 2021----
Mate PocsinTowards Data ScienceThe Danger of Random SeedsA case study in R about how being pedantic with your random seeds can lead to unwanted results.·5 min read·Aug 23, 2021----
Mate PocsinGeek CultureWhy You Should Never Trust Data Science Blog PostsExcept for this one of course. You can trust this one! Or can you?·12 min read·Jun 30, 2021----
Mate PocsinTowards Data Science5 Common Misconceptions about Linear Regressions·11 min read·May 29, 2021--2--2
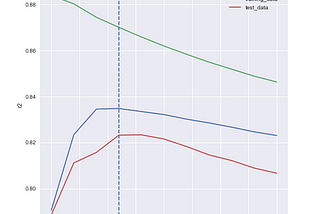
Mate PocsinTowards Data ScienceHyperparameter Tuning in Lasso and Ridge Regressions·12 min read·May 16, 2021--1--1