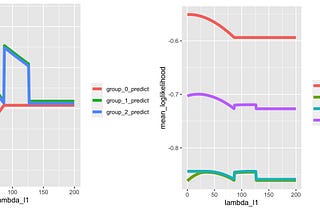
Published inTDS ArchiveUnderstanding L1 Regularisation in Gradient Boosted Decision TreesA thorough look with an example in LightGBM and RNov 1, 2022Nov 1, 2022
Published inTDS ArchiveUnderstanding min_child_weight in Gradient Boosting Decision TreesDo you really know how this hyperparameter works?May 18, 20221May 18, 20221
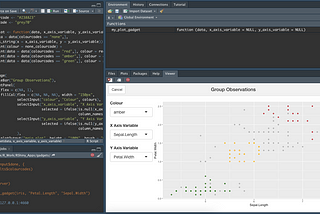
Published inTDS ArchiveR Shiny GadgetsHow to help your RStudio work with interactive appsApr 3, 2022Apr 3, 2022
Published inTDS ArchiveUnderstanding How a Gradient Boosted Tree Does Binary ClassificationA step-by-step recalculation in LightGBM and R, from data to predictions, using the banknotes datasetDec 4, 2021Dec 4, 2021
Published inTDS ArchiveThis Week’s Unboxing: Gradient Boosted Models’ “Black Box”Step-by-step recalculation of the hidden model results, using R and LightGBMNov 11, 20211Nov 11, 20211
Published inTDS ArchiveHow to Handle the Exposure Offset with Boosted TreesThree ways to move from GLM/GAM to a GBM model in insurance.Aug 28, 2021Aug 28, 2021
Published inTDS ArchiveThe Danger of Random SeedsA case study in R about how being pedantic with your random seeds can lead to unwanted results.Aug 23, 2021Aug 23, 2021
Published inGeek CultureWhy You Should Never Trust Data Science Blog PostsExcept for this one of course. You can trust this one! Or can you?Jun 30, 2021Jun 30, 2021
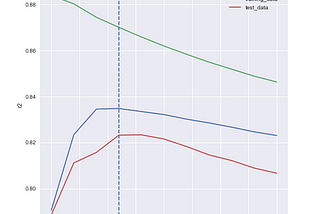
Published inTDS ArchiveHyperparameter Tuning in Lasso and Ridge RegressionsMay 16, 20211May 16, 20211